



The utilization of machine intuition has been leveraged in countless industries, from voice recognition, to suggestive search on the web, down to CCTV image processing. As the design process in architecture happens mostly through the medium of 3D software (Rhinoceros 3D, Maya, 3DSmax), our discipline could also benefit from the help of machine-generated suggestions.
This is the goal of this independent study: study and propose a way to assist designers, through suggestive modeling. As designers draw in 3D space, a machine-learning-based algorithm would be able to assist the designer by proposing alternative, similar or complementary options to them. In a nutshell, we would look into precedent works in the field of suggestive modeling, to finally come up with a methodology and a tool that would be able to suggest models to designers as they draw. Ultimately, our goal is to find an answer to the following question: Can machine learning assist designers in the design process, by suggesting potential design options?
As designers are increasingly with 3D modeling software, improving softwares in order to bridge the gap between technicity and intuition is a growing concern. Our project is set right on the edge between these two imperative, and aims at achieving the following:
Being able to query 3D objects matching the characteristics of an object drawn by a potential user relies on features comparison. Away from standard geometric descriptive metrics, convolutional neural networks offer a simplified and more comprehensive option to compare geometries.
Instead of simple metrics, CNNs take images as input, passing their pixel representation to a succession of layers of "neurons". A CNN model tunes weights in each neuron, while outputting a prediction at its last layer. Through successive phases of training and validation, we are able to estimate the accuracy of our model, and further tune weights to maximize accuracy. Once fully trained, a CNN model will predict the "class", or category of a given object image representation.
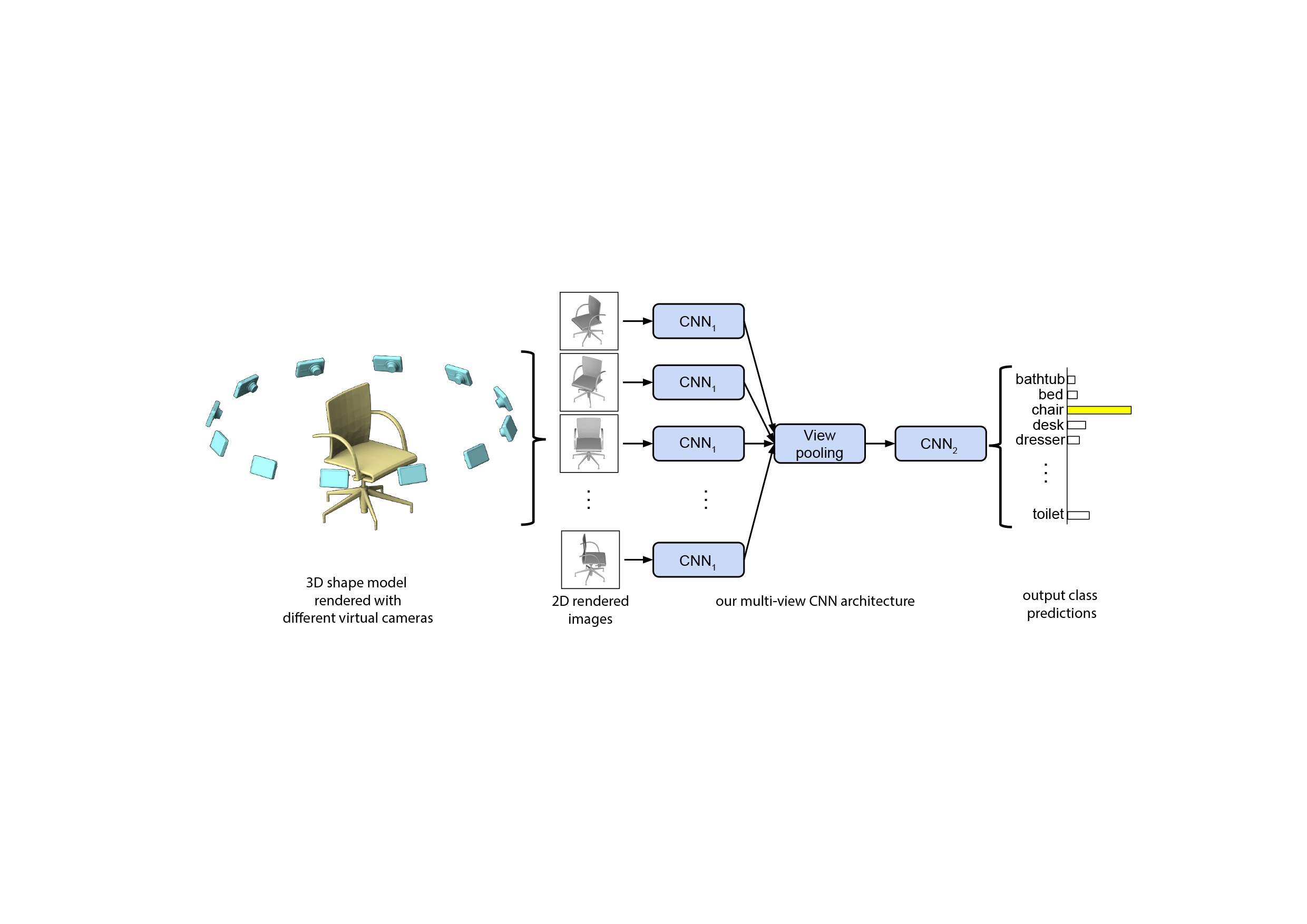
This first paper (1) presents a standard CNN architecture trained to recognize the shapes’ rendered views independently of each other and shows that a 3D shape can be recognized even from a single view at an accuracy far higher than using state-of-the-art 3D shape descriptors. Recognition rates further increase when multiple views of the shapes are provided.
In addition, a novel CNN architecture is introduced, which combines information from multiple views of a 3D shape into a single and compact shape descriptor offering even better recognition performance. The same architecture can be applied to accurately recognize human hand-drawn sketches of shapes.
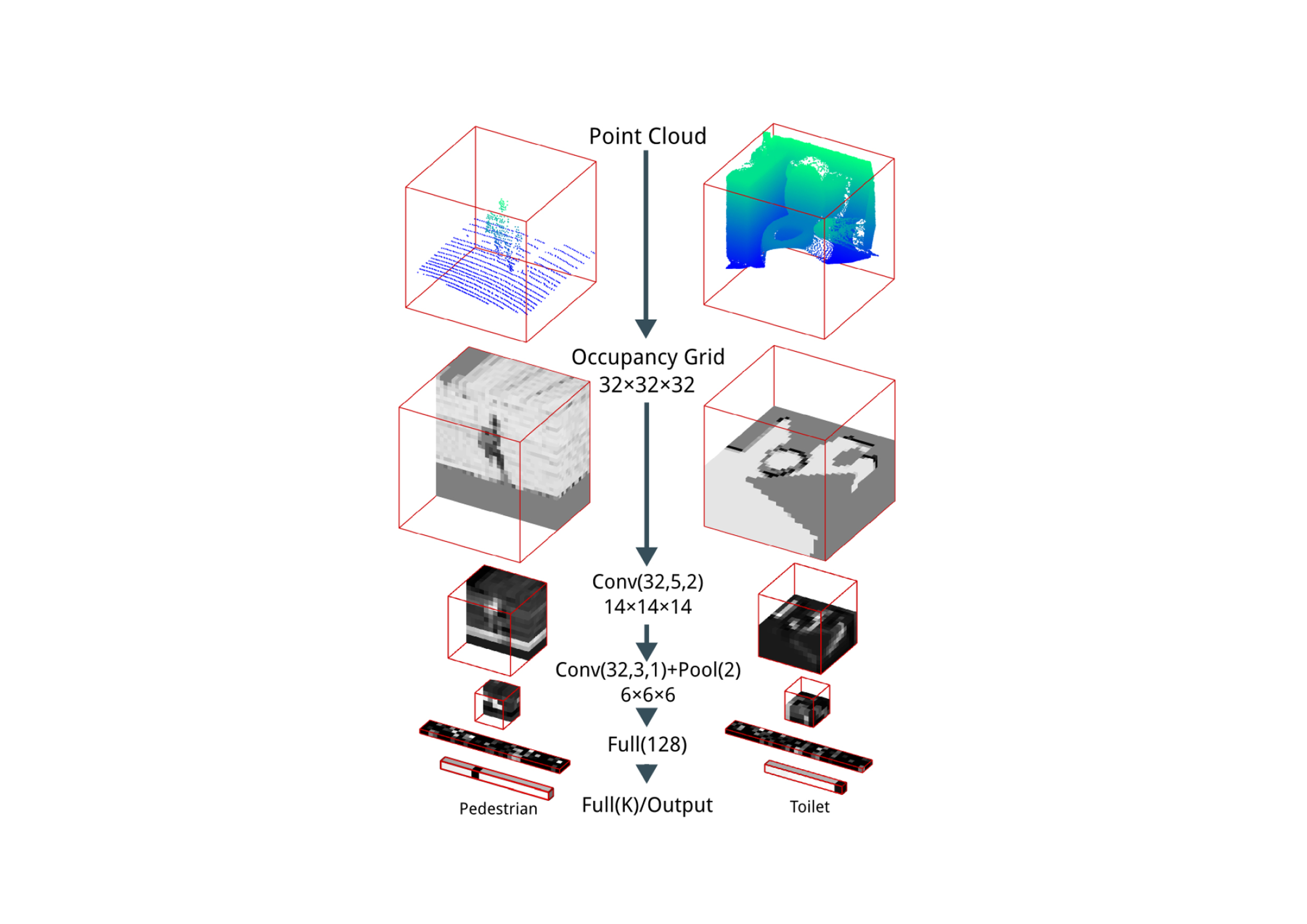
To leverage the growing amount of point cloud databases, resulting from the increasing availability of LiDar and RGBD scanners, this paper (2), proposes a “VoxNet”. This model’s architecture aims at tackling the issue of vast point cloud processing and labeling, by integrating a volumetric Occupancy Grid representation with a supervised 3D Convolutional Neural Network (3D CNN). The results are evaluated on publicly available benchmarks using LiDAR, RGBD, and CAD data. VoxNet ultimately achieves accuracy beyond the state of the art while labeling hundreds of instances per second.
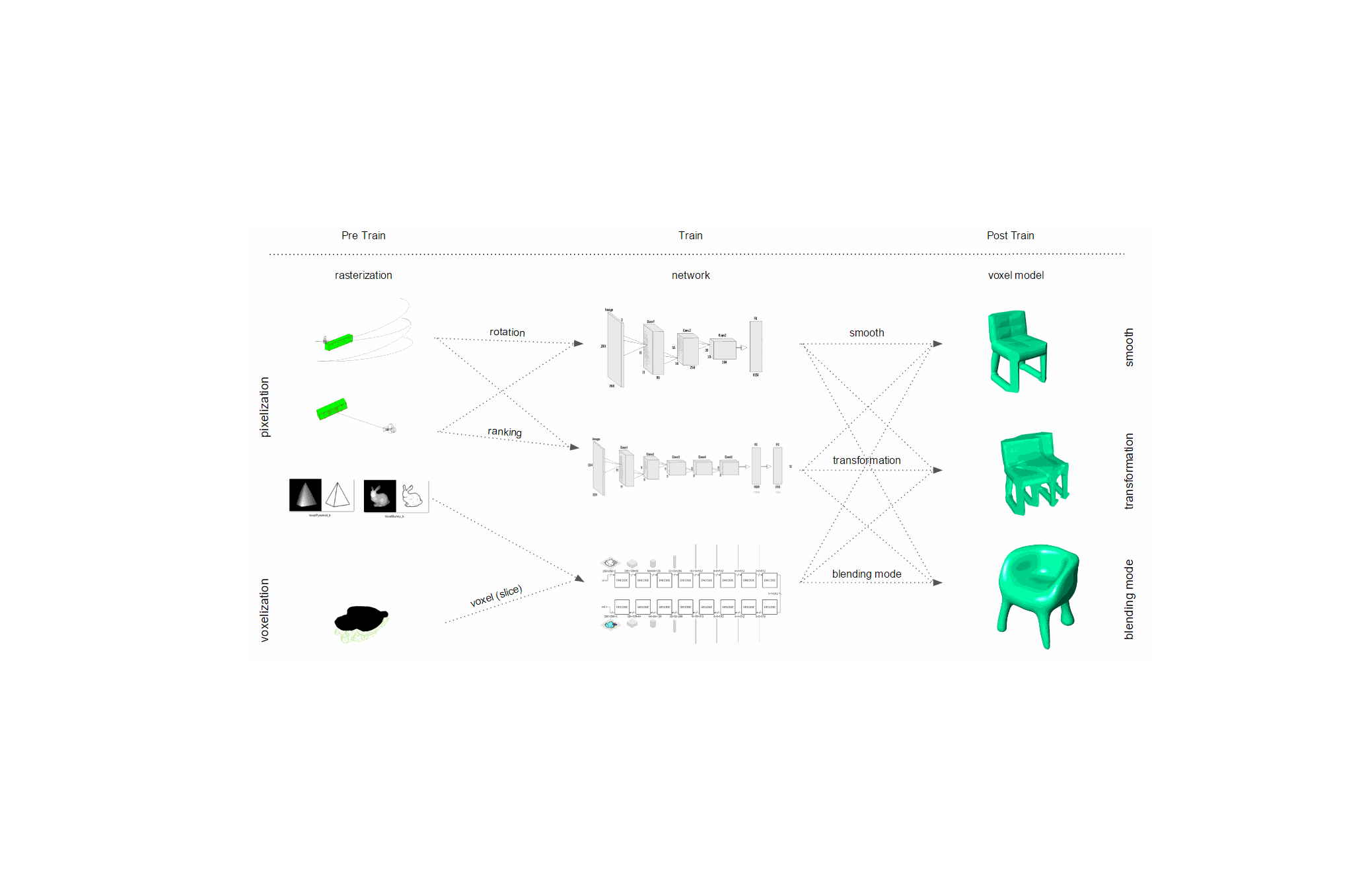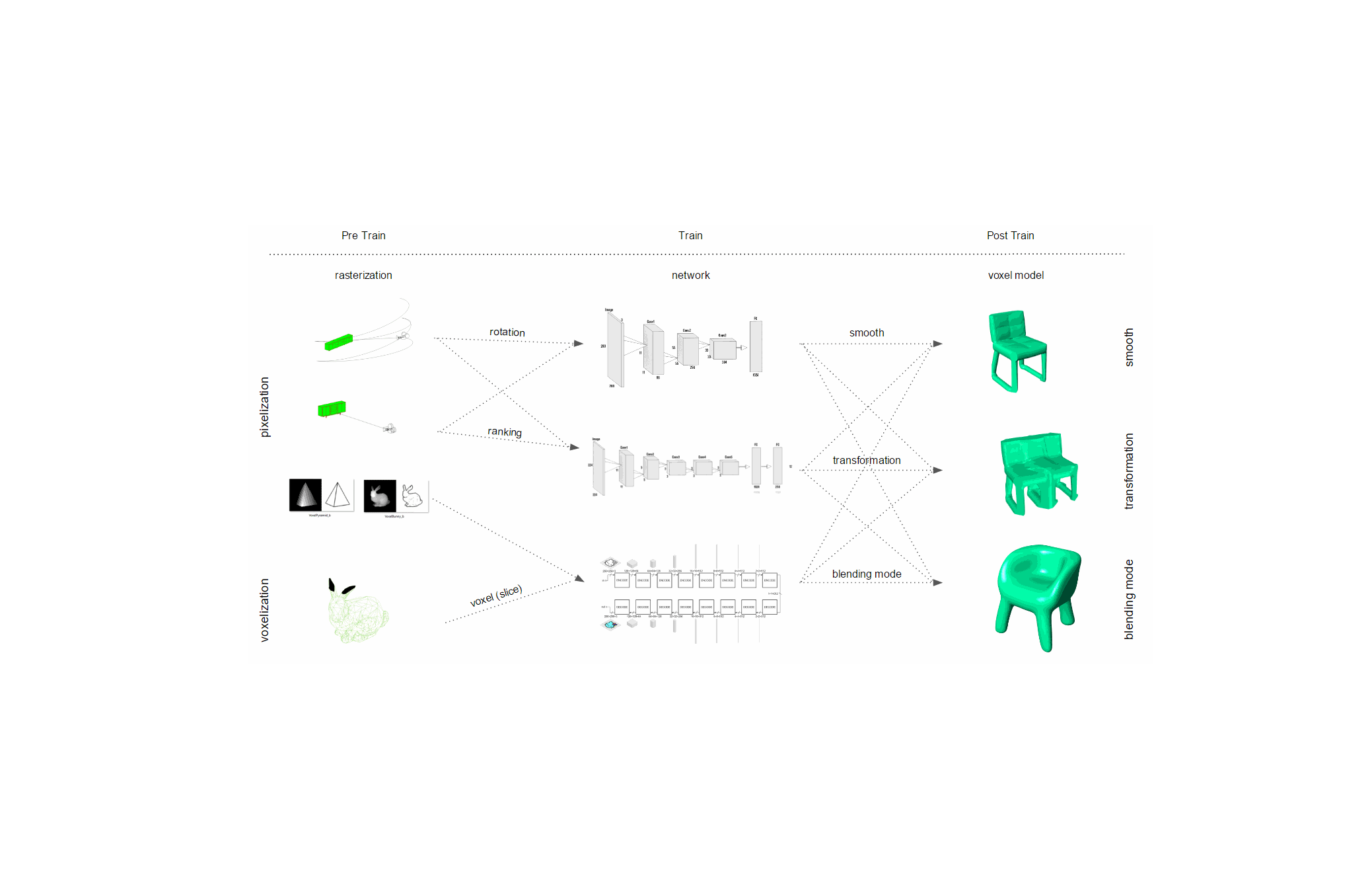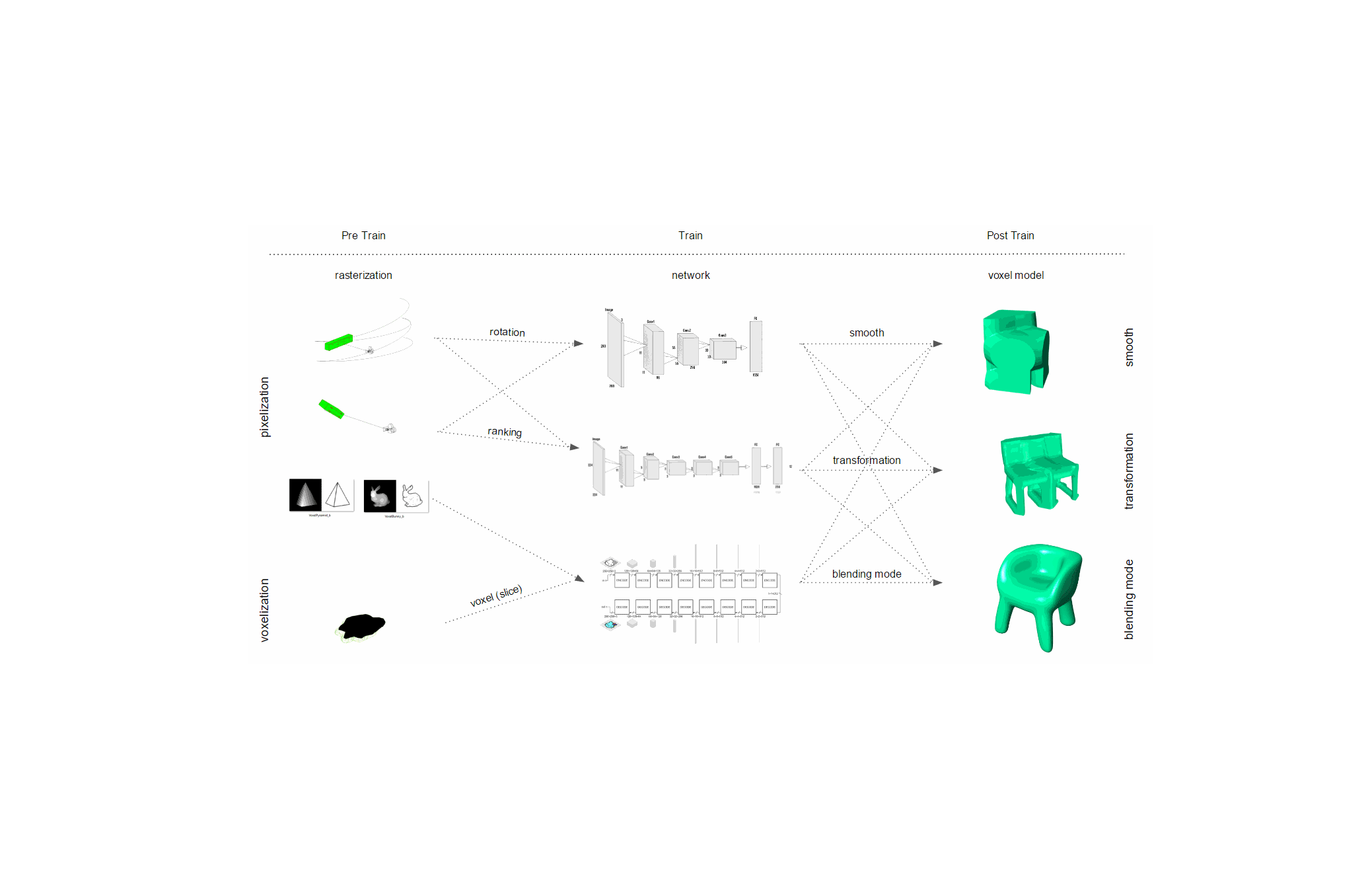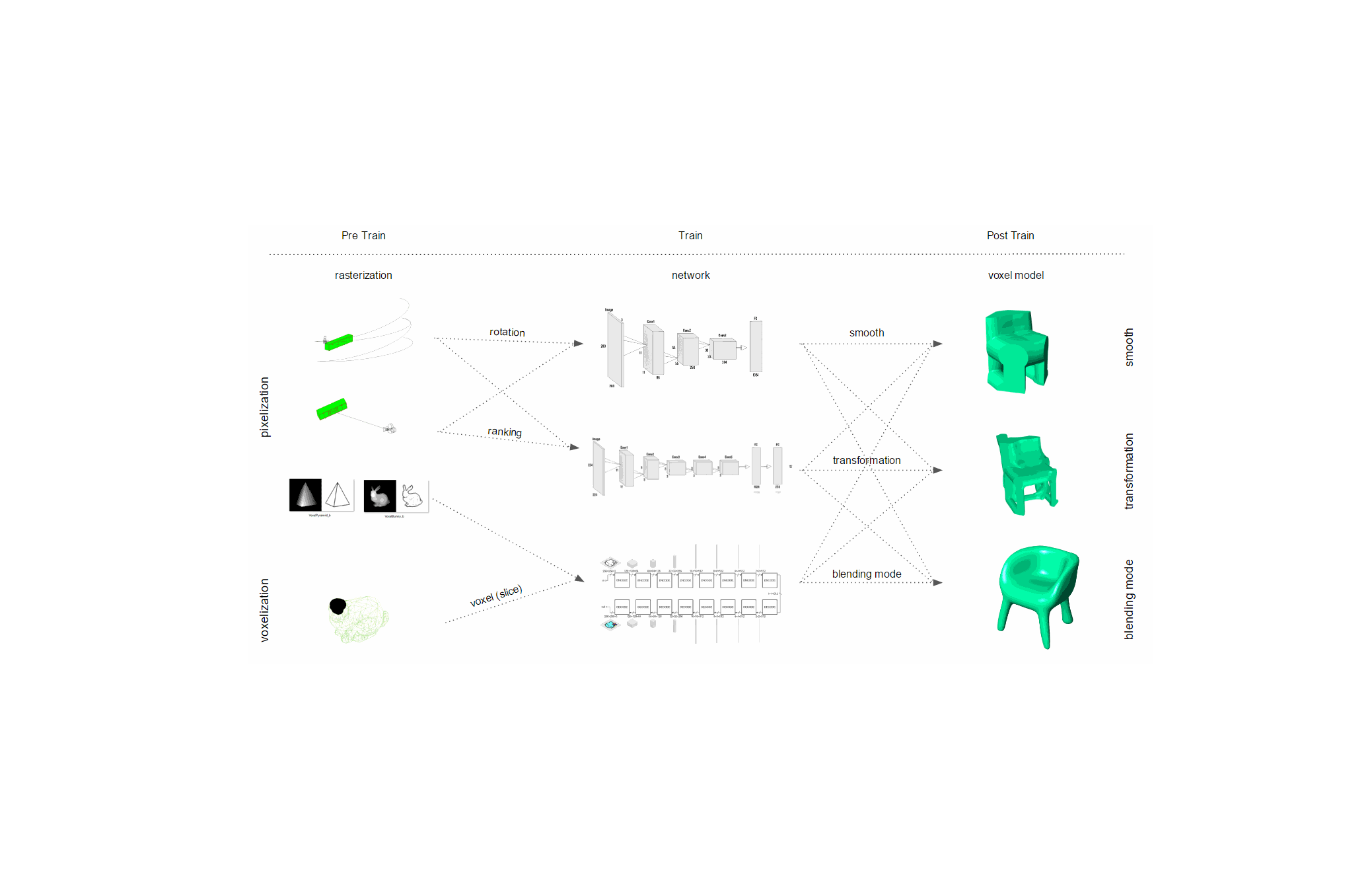
This last paper (3) explores the opportunities of voxel modeling with Machine Learning.
The notion of voxel modeling is first introduced and compared to traditional model technic. Concepts like pixel map and graph representation are explained, to finally examine prototypical implementations of proposed design systems or workflows based on the process from rasterization of space and geometry with Machine Learning.
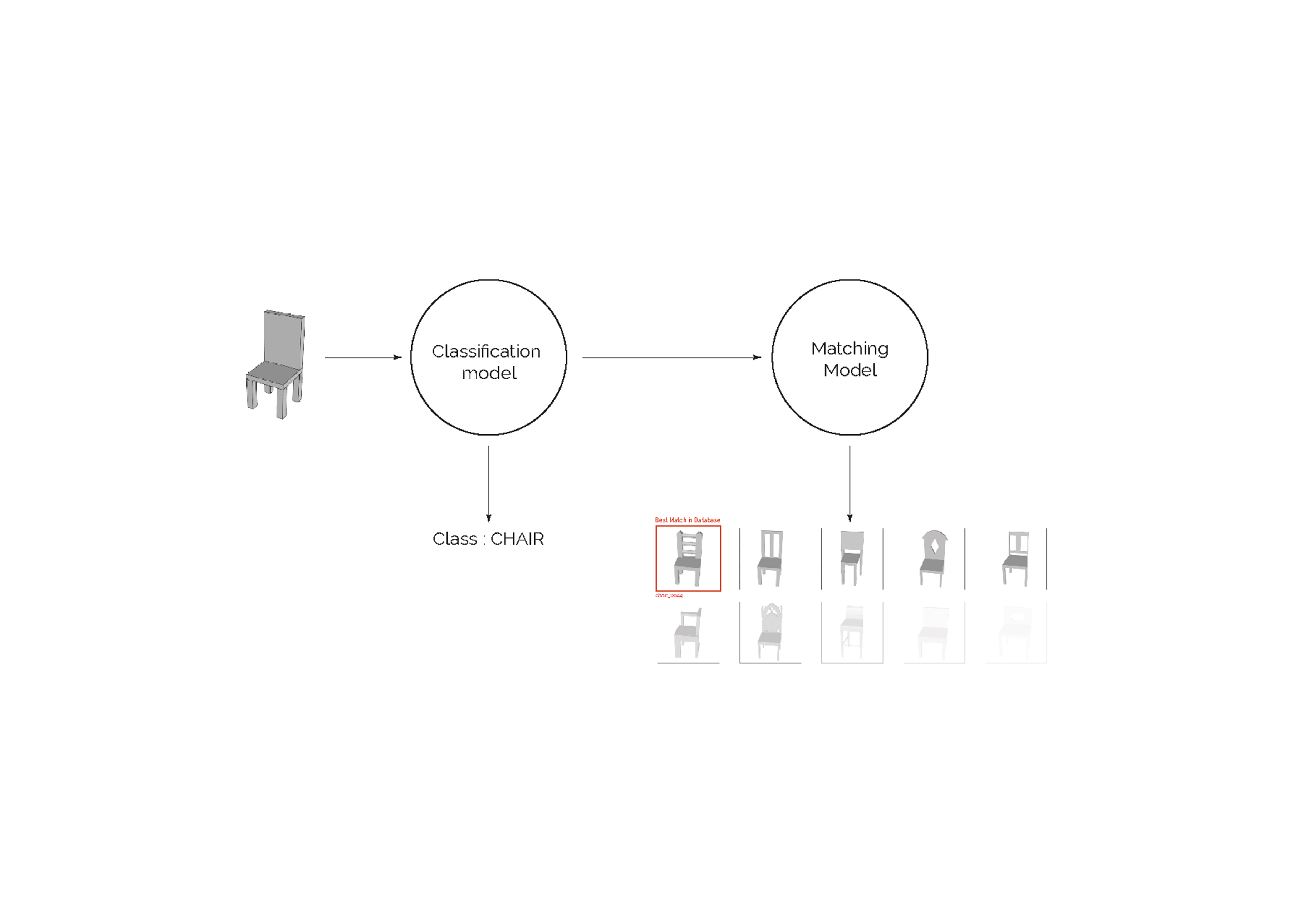
Our approach in this project is to recognize the object being drawn by the user and serve him similar objects by simply using the shape of the object as proxy.
In short, the model we are designing here has two main tasks:
By nesting two different levels of models (a classifier and “matcher”), we might be able to perform this two -steps process. Each model will be trained on images of 3D models and will be then tested on images of the object modeled by the user.

First step was to generate a training database. For that purpose, we extracted information from:
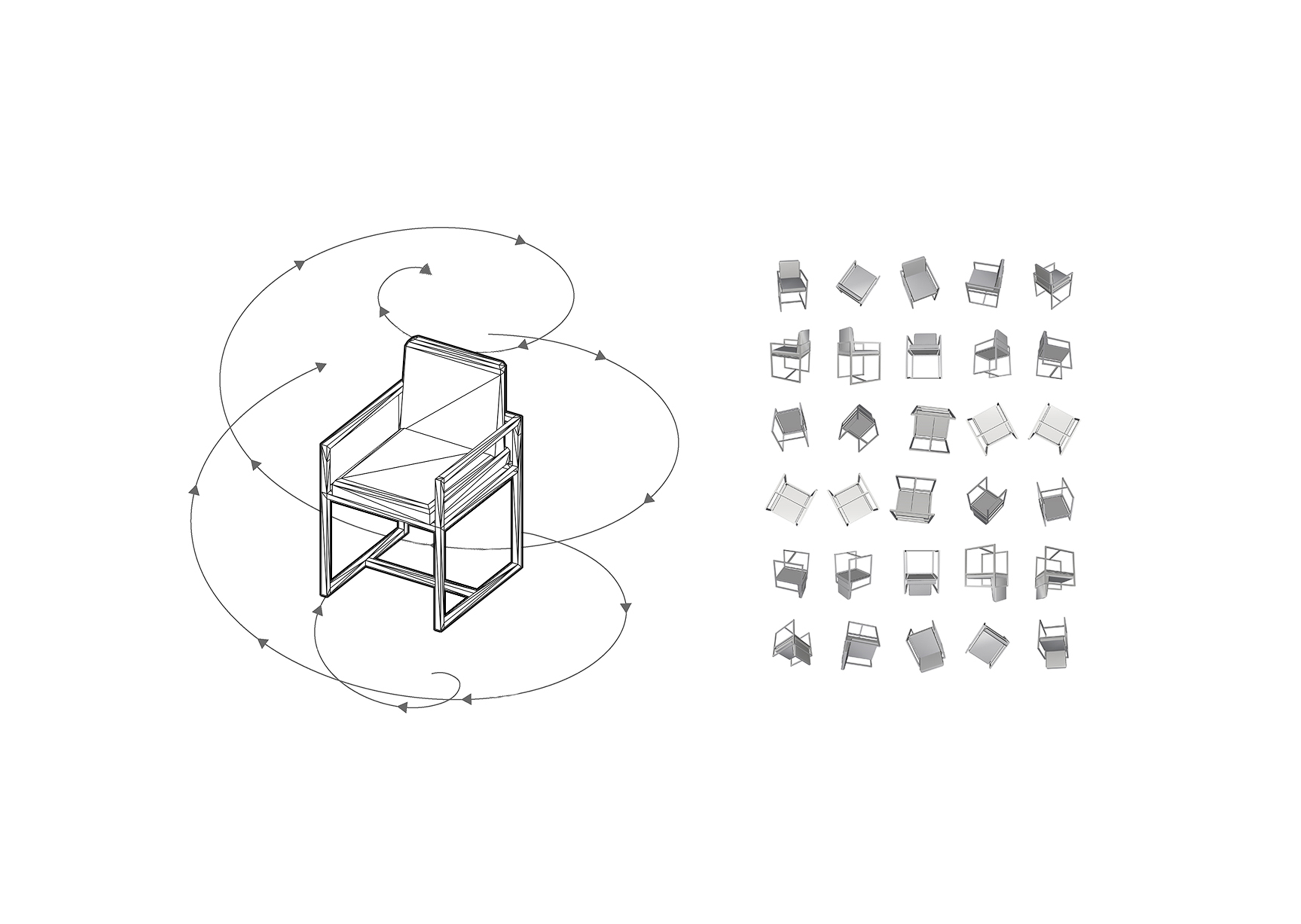
From the ShapeNet database, we were able to download up to 2.330 classified 3D models, of 14 specific classes:Using Rhinoceros and Grasshopper, we then scripted a tool to create both our training and validation sets. A camera, rotating around each successive object will take shots of the object at specific angles, and save jpg images in our directory.
For each object we take 30 images for training, and 10 for validation, while keeping a white background.
The first step of our model is to classify the object given by the user. Our goal is to train this first model on extensive amounts of 3D objects' images, while validating its performance on sets of other objects’ images, belonging to similar classes as the training set. The input for testing will be an image of the user’s 3D object, and the output a label (one of the 14 classes we defined earlier).
Several parameters heavily impact the accuracy of the trained classifier:
At this point we iterate between different options and aim at increasing the model overall accuracy on the validation set. The training set consists of images of objects of all 14 classes, gathered as one batch. The validation set, is composed of one batch of images (less images per object) of different objects from the 14 classes, taken along a similar capture path.
Having limited resources, we cannot afford to train from scratch. Using some transfer learning comes in handy, as it offers the possibility of boosting our model accuracy, while by passing days of training. We add as first layers of our model a VGG16 pretrained model from Keras. This boosts our accuracy by 32%!

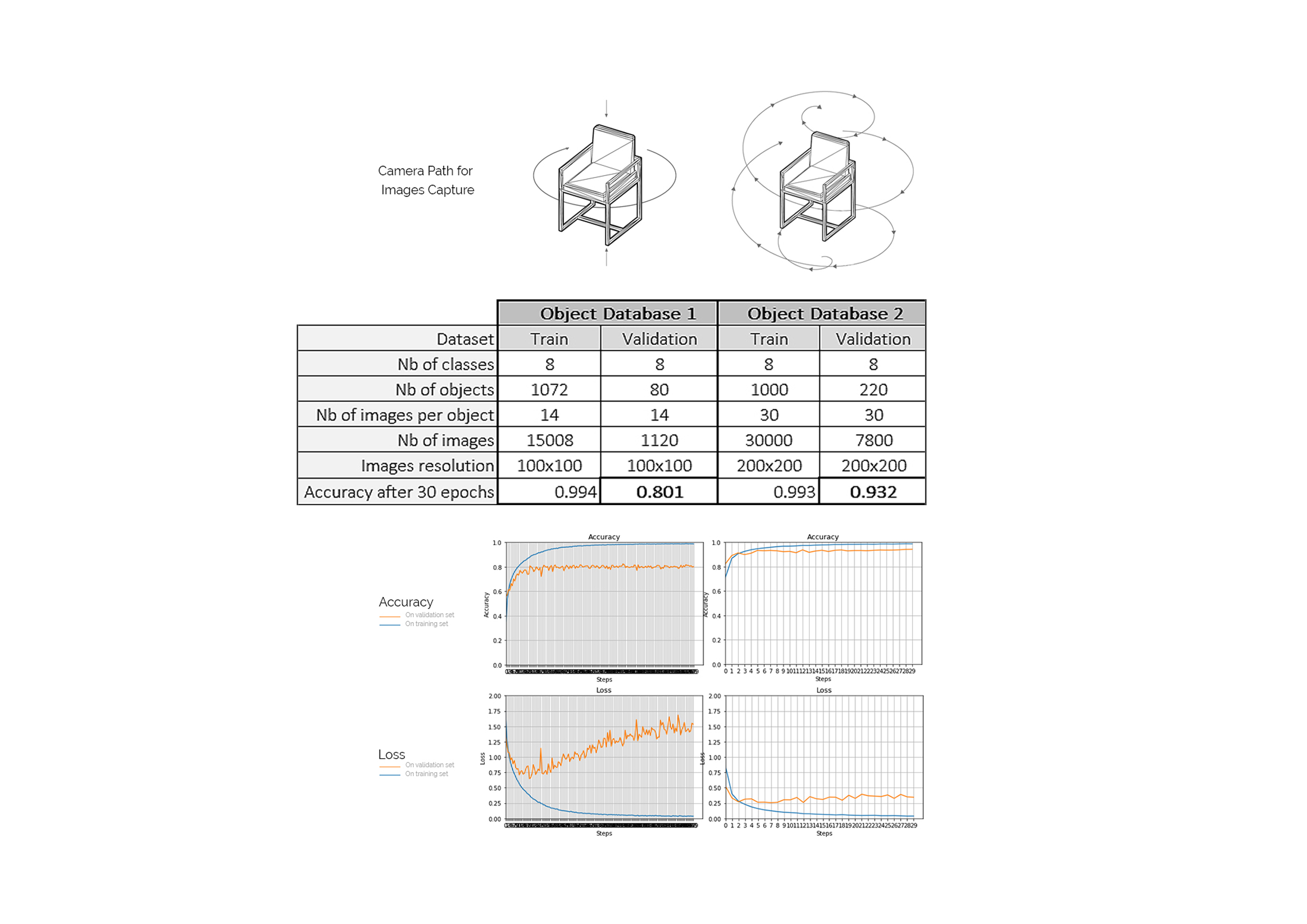
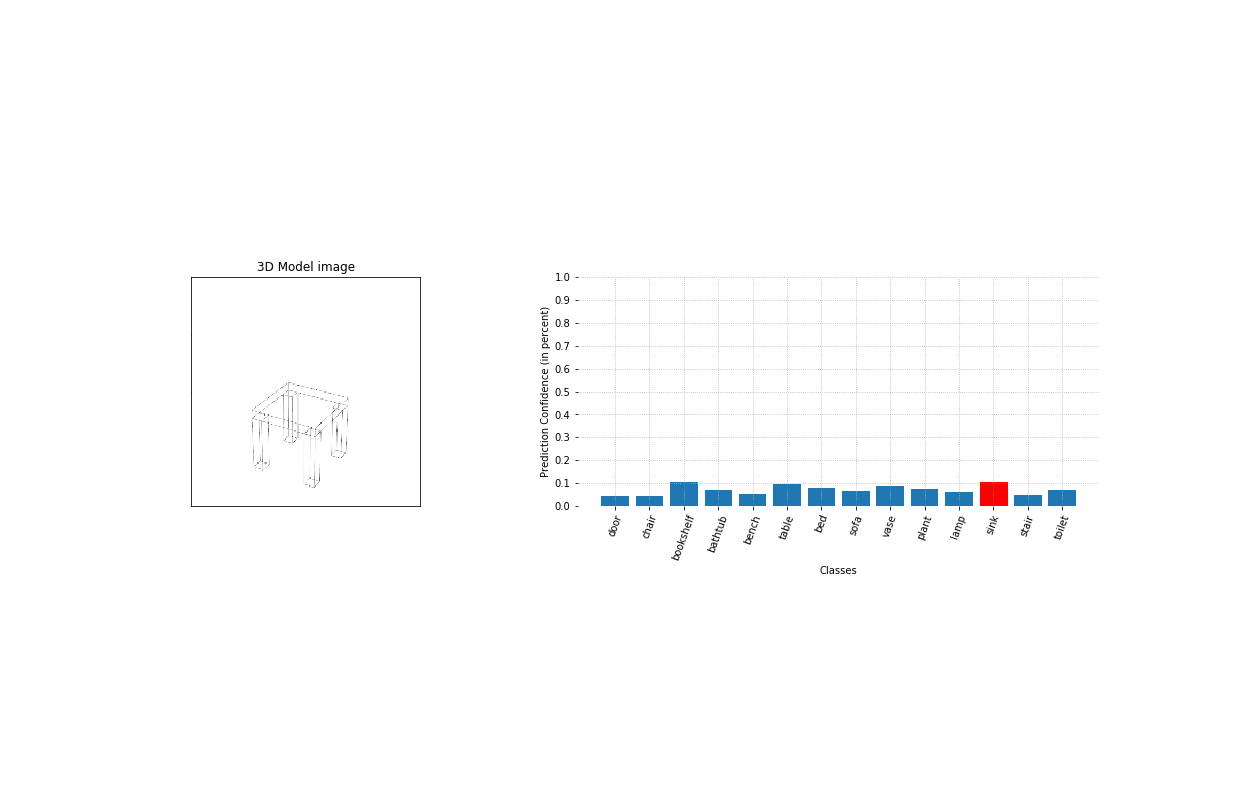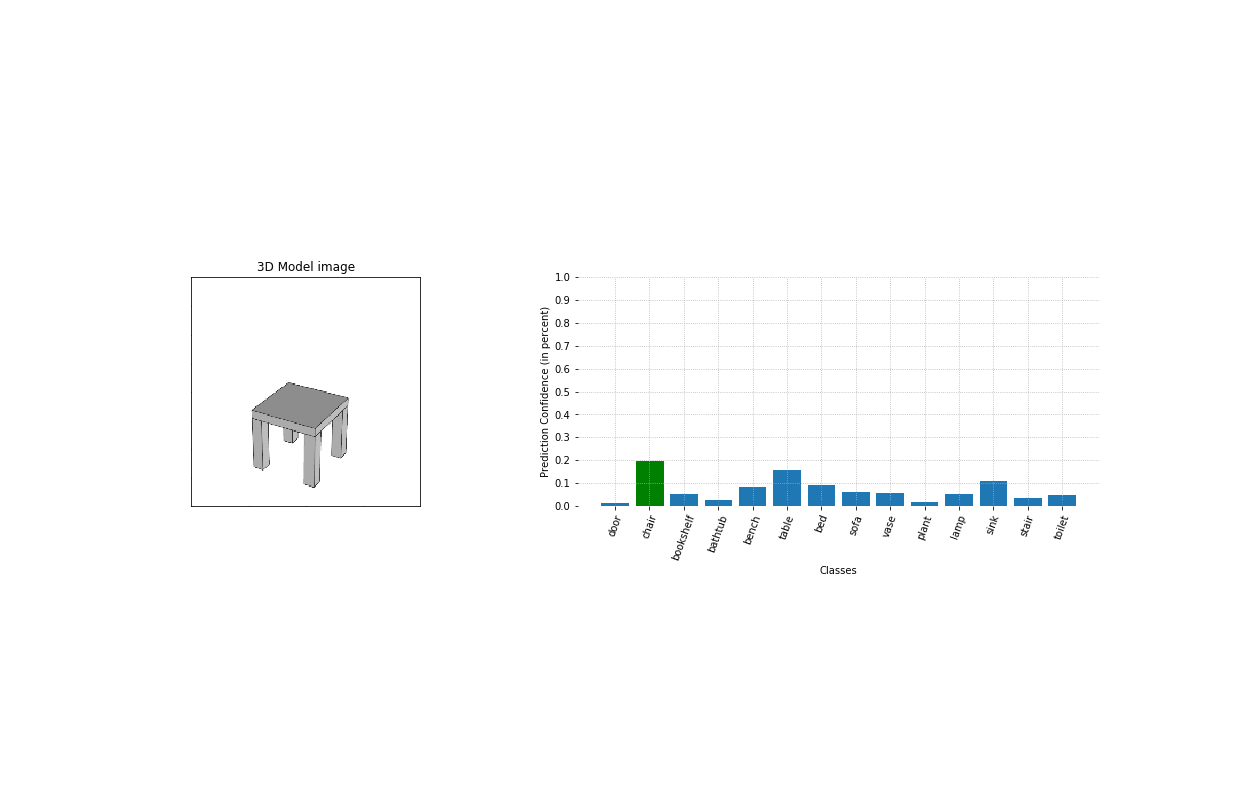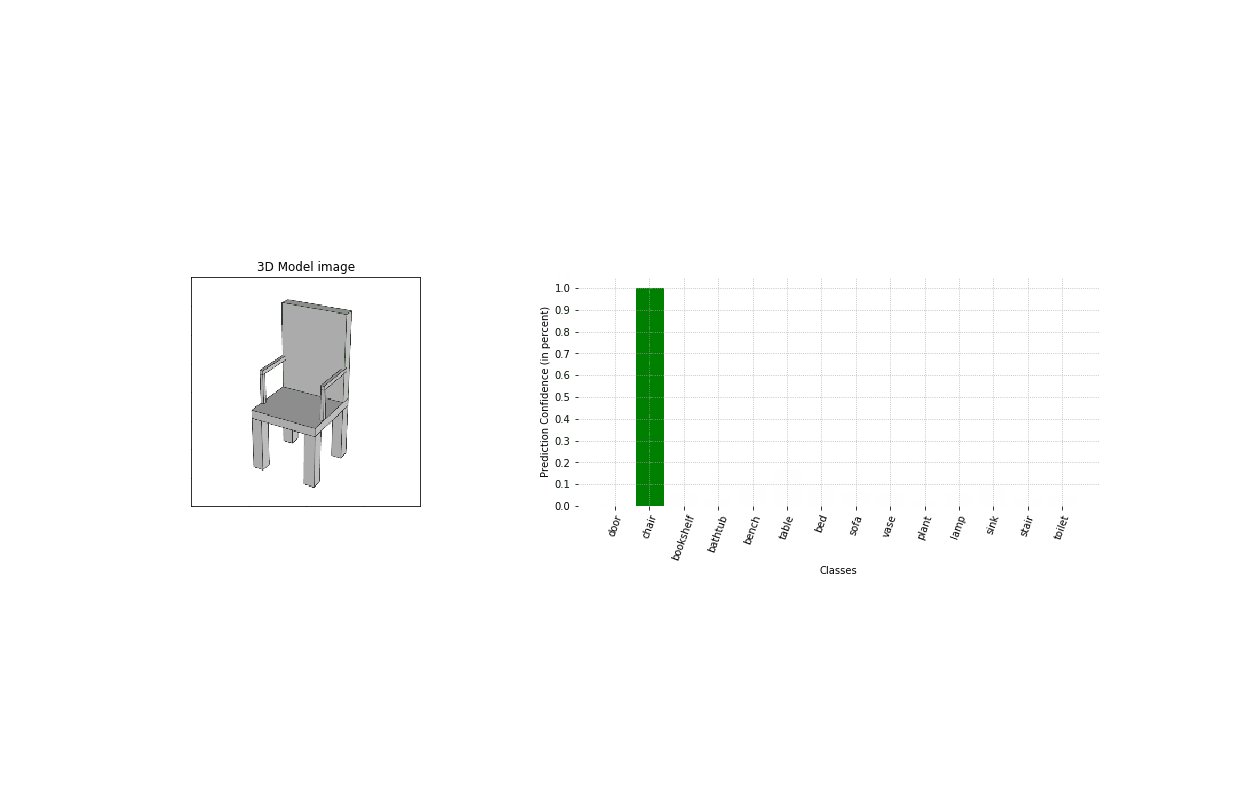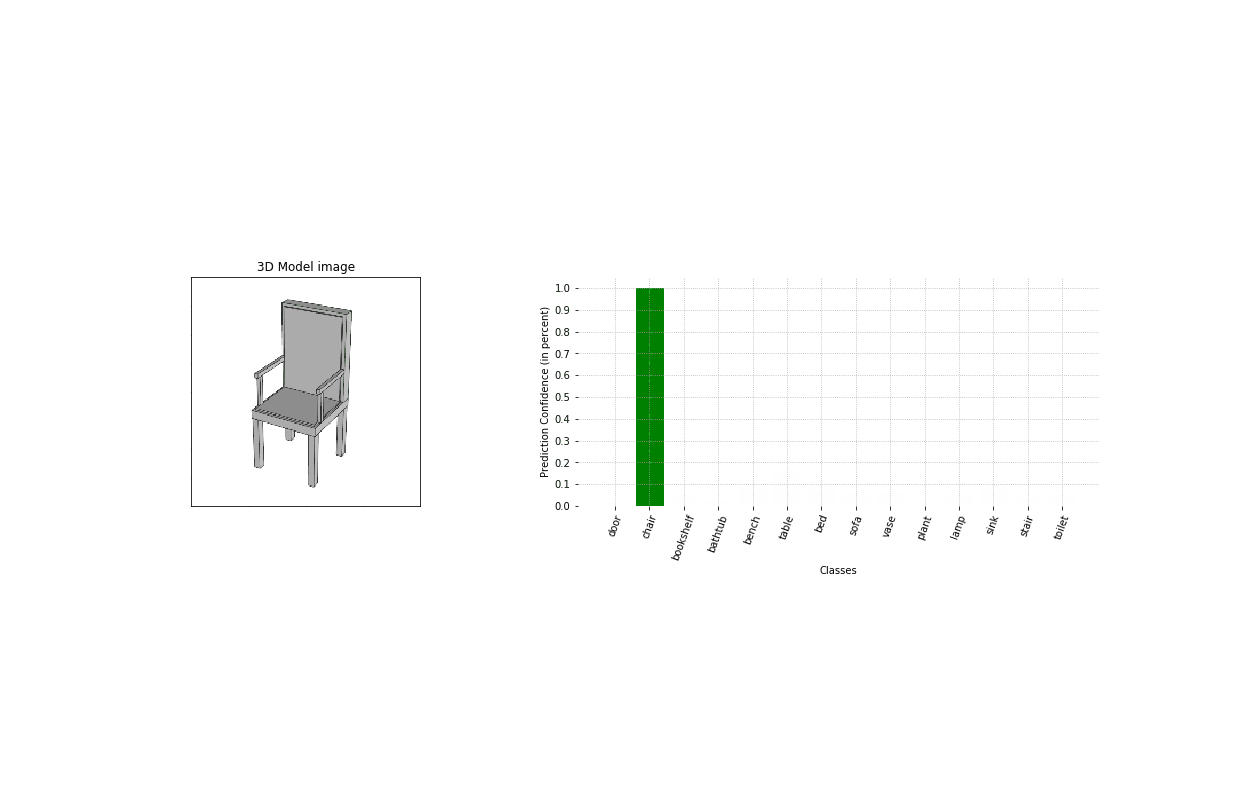
After several evaluations it comes clear that the following parameters influence greatly the performance of the overall model:
Ultimately, we settle for a classifier using 200*200px images, with a spherical camera path, 30 images per object for training, and 10 for validation. After 30 epochs, we finally obtain an accuracy on the validation set of 93%.
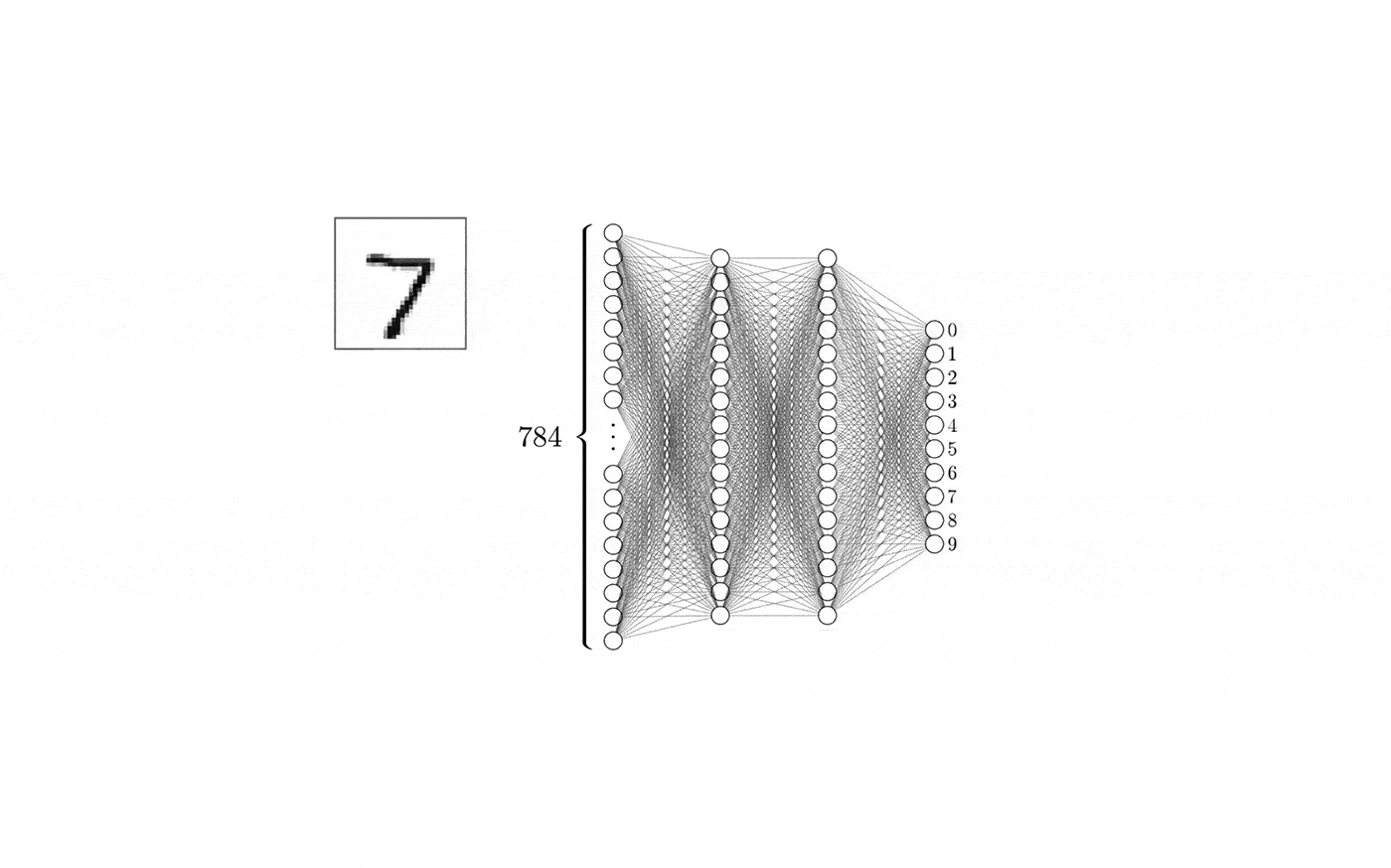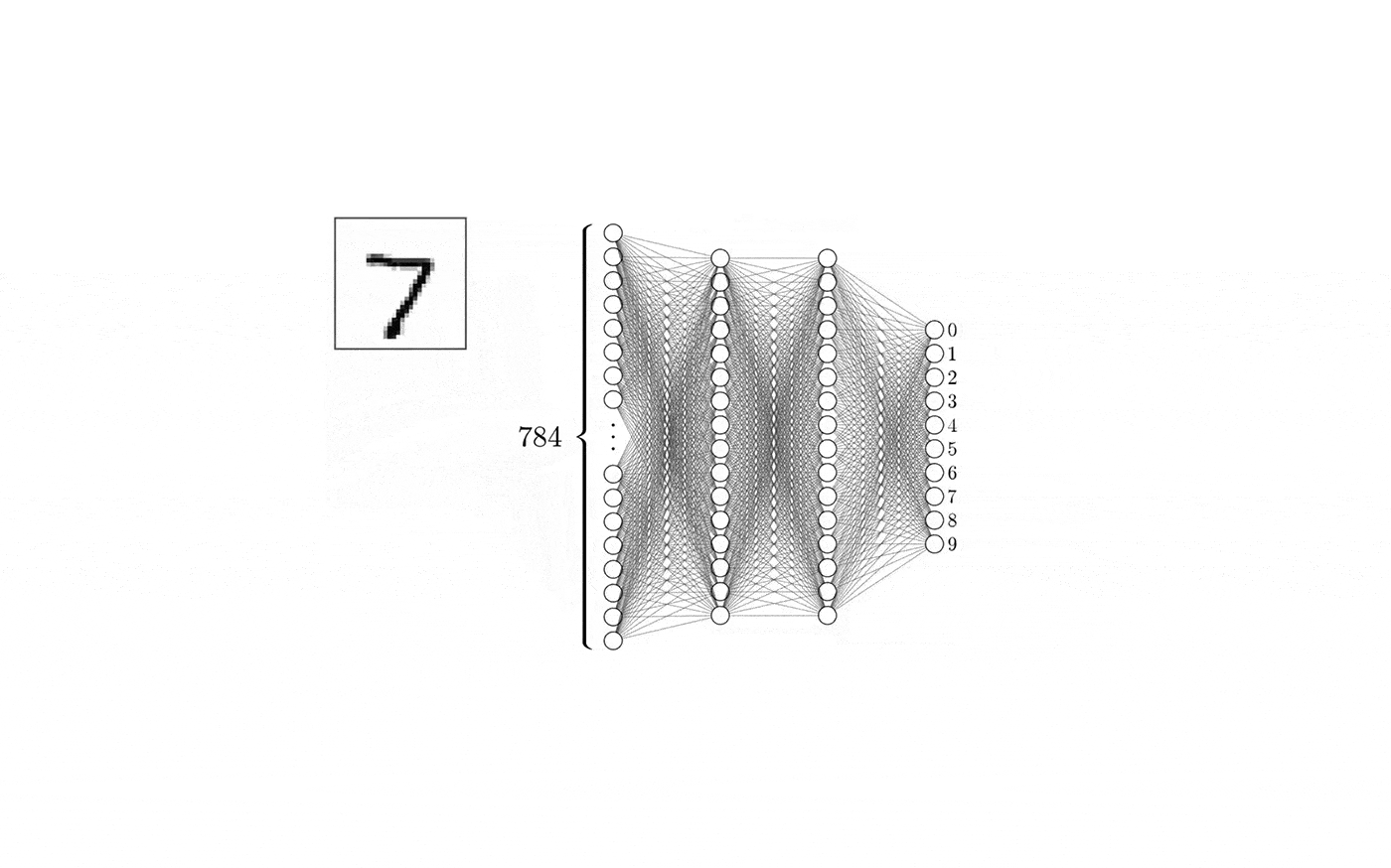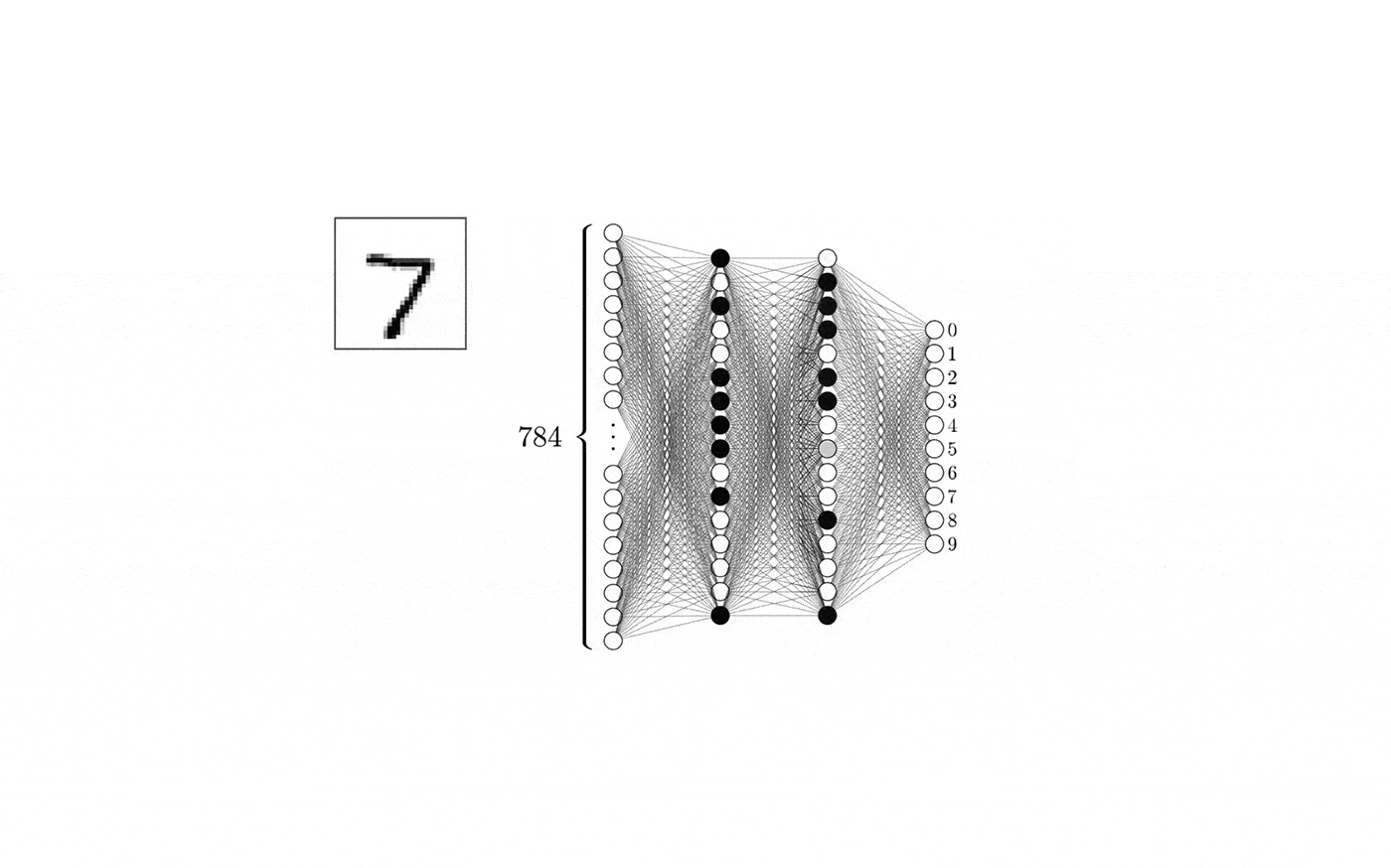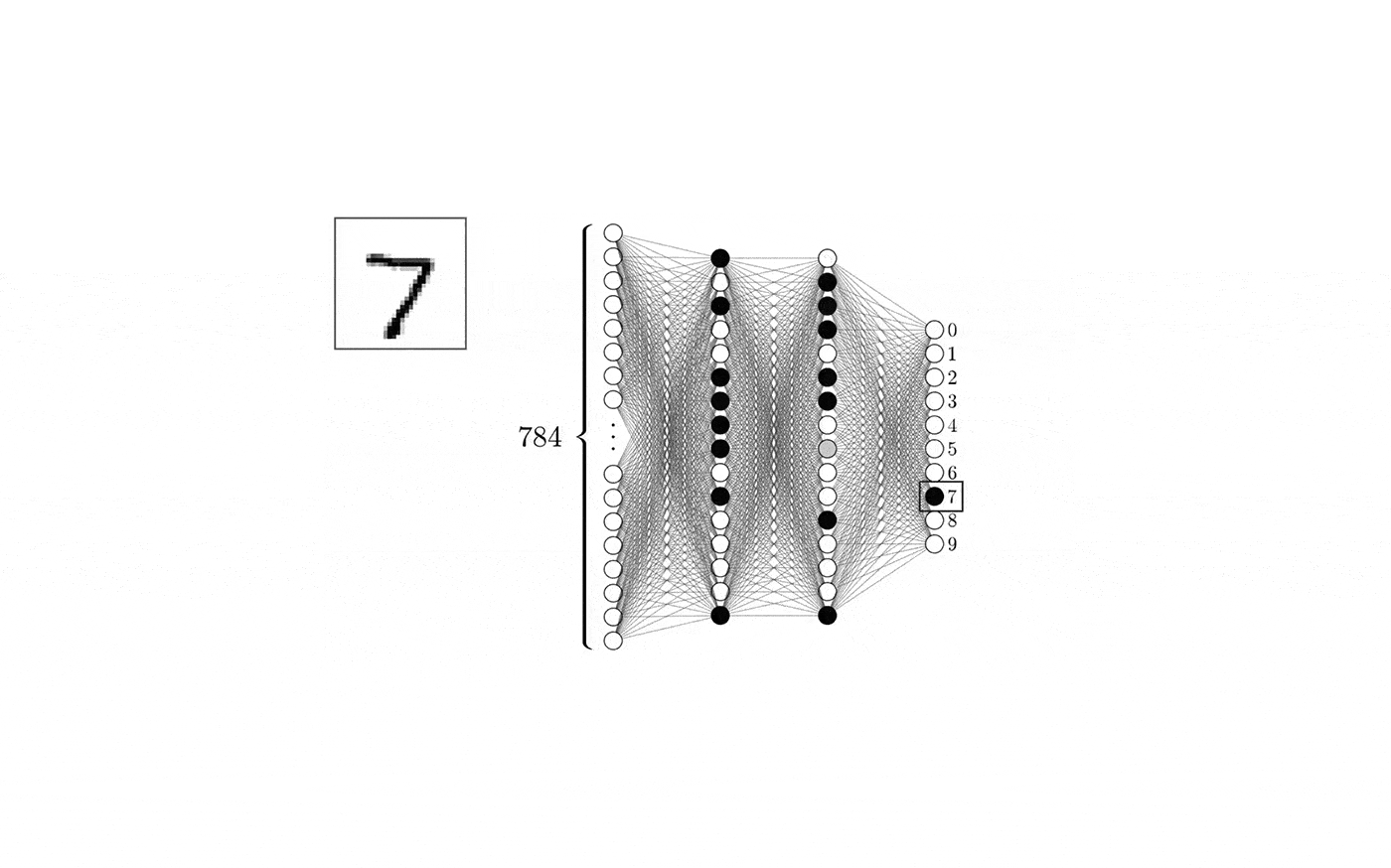
Using some test objects modeled by the user, we test our tool for different modeling stages (image here on the left). As it appears, it is able to detect the nature of the object very early on during the design process.
In a second step, our model attempts at finding ideal matches in an extensive database of 3D models. If the classification model helps at narrowing down the search, the matching model ranks all 3D models from a given class from “most resembling” to “least”.
Our matching model is another convolutional neural network, trained on images of objects of a given class, and validated on the same objects, with views taken from different angles. For testing, our input will be one image of the user 3D object, and the output will be a list of all object in our database of the identified class, ranked by resemblance. We therefore have to train one model per class.
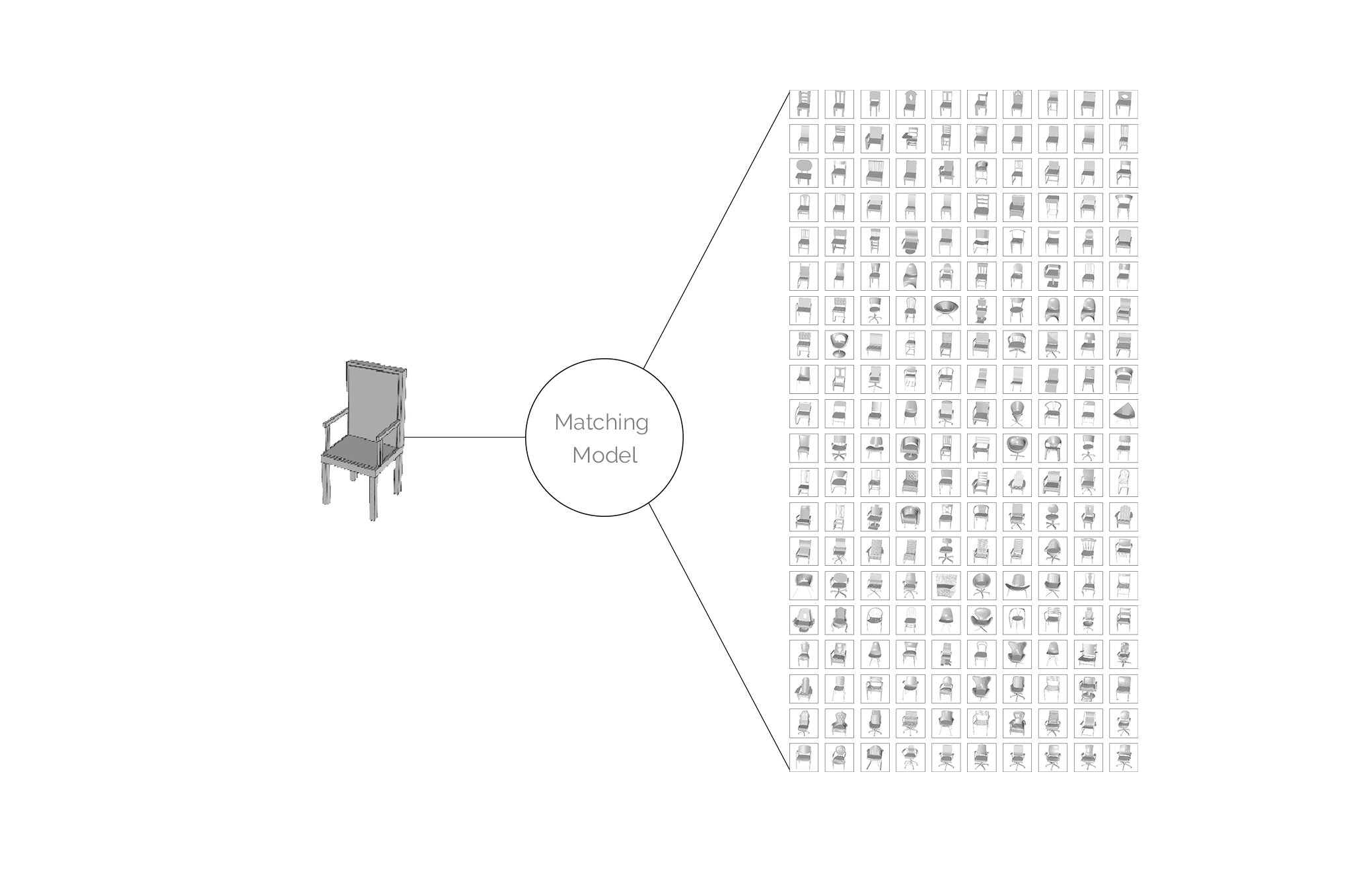

As we train a model for each individual class, we are able to nest the classification model and the matching models as one single tool. We can now process one image of a given 3d object, that will be first classified, and finally matched with similar objects present in our database. At the same time, our model outputs some value of prediction confidence to help us gauge how strong the resemblance between the original model and the match actually is.
The test has been run for 7 objects of different classes and are here displayed on the left.
Moving on to the next step, this project is called to be refined and improved in the followings ways: (1) translate this to plan generation, using the power of nested models to structure and organize suggestions (2) integrate this model with standard 3D software such as Rhinoceros of Revit as an actual plugin, (3) complement the suggestive model with metadata, to not solely rely on topological features, but also more comprehensive descriptors.
More broadly, this project is the opportunity to recognize the change happening in the architectural discipline, where machines and information can be leveraged to enhance our work and technic. Far from the idea of “automating” the architect’s work, suggestions are a way to broaden the set of possibilities, and references used by architects and designers, without tempering with the design process. More deeply, suggestive design is a stepping stone towards a more integrated practice of CAD, where computers and architects truly complement each other during the design phase.